在数字化娱乐浪潮中,Netflix凭借其卓越的数据处理能力,不仅重塑了用户收视习惯,更重新定义了内容产业的运作模式。通过不断演进的数据处理架构,Netflix成功将海量用户数据转化为精准的收视率预测和个性化推荐,实现了从内容平台到数据驱动型企业的华丽转型。
第一阶段:云端迁移与基础架构建设
Netflix早在2008年就开始向亚马逊云服务(AWS)全面迁移,这一战略决策为其后续的数据处理能力奠定了坚实基础。通过利用AWS的弹性计算和存储资源,Netflix建立了可扩展的数据管道,能够处理每日产生的数PB级别用户行为数据,包括播放记录、搜索查询、评分和观看时长等多元信息。
第二阶段:实时流处理系统的构建
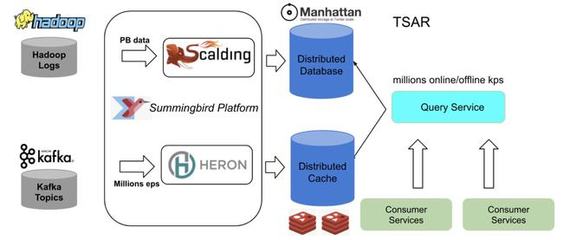
随着用户规模急剧扩张,Netflix开发了名为"Keystone"的实时数据流处理平台。该系统基于Apache Kafka和Apache Samza构建,能够实时处理每秒数百万条事件数据。这种实时处理能力使得Netflix可以在用户观看过程中即时调整推荐算法,实现真正的动态个性化体验。
第三阶段:机器学习与深度学习集成
Netflix将机器学习深度整合到数据处理流程中,开发了专门的机器学习基础设施"Metaflow"。这个平台支持从数据预处理、特征工程到模型训练和部署的全流程管理。通过分析用户观看模式、设备类型、地理位置等数百个特征维度,Netflix的推荐系统能够精准预测用户的收视偏好,显著提升用户粘性和内容消费时长。
第四阶段:多云架构与数据治理
为确保数据处理的高可用性和合规性,Netflix采用了多云战略,在AWS基础上引入了Google Cloud Platform。同时建立了完善的数据治理框架,包括数据质量监控、隐私保护机制和合规性检查,确保在满足全球各地数据法规要求的持续优化数据处理效能。
存储服务的演进:从单一到分层
在数据存储方面,Netflix经历了从关系型数据库到多层级存储体系的转变。当前架构包括:
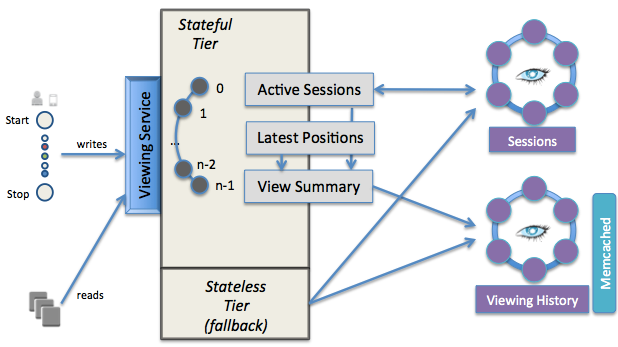
- 实时缓存层:使用Memcached和EVCache支持毫秒级响应
- 在线存储层:采用Cassandra和DynamoDB处理结构化数据
- 离线存储层:利用S3和HDFS存储历史数据供批处理分析
- 数据仓库:基于Iceberg和Presto构建企业级数据湖
数据处理服务的创新实践
Netflix开创性地将数据处理服务产品化,内部团队可以像使用公共服务一样调用数据处理能力。通过"Genie"作业调度系统和"Mantis"实时流处理框架,实现了数据处理任务的标准化和自动化管理。这种服务化架构大大降低了数据使用的技术门槛,使得产品团队能够快速实验和迭代新的推荐算法。
效果与影响
这套不断演进的数据处理架构为Netflix带来了显著的业务价值:
- 用户参与度提升:个性化推荐贡献了超过80%的观看内容
- 内容投资优化:通过收视预测模型显著提高了原创内容成功率
- 运营效率提升:自动化数据处理流程减少了70%的人工干预
- 全球化扩展:支持在190多个国家提供本地化服务
Netflix继续在边缘计算、联邦学习和隐私增强技术等领域进行探索,致力于在保护用户隐私的进一步提升数据处理和个性化服务的能力。这种以数据为核心的架构演进,不仅巩固了Netflix在流媒体领域的领先地位,更为整个行业树立了数据处理架构演进的典范。