全链路压测是保障分布式系统在高并发场景下稳定性的关键手段。在有赞这样复杂的电商业务生态中,数据处理与存储服务作为压测的基石,其方案的设计与实施直接决定了压测的真实性、有效性与安全性。本文将深入剖析有赞全链路压测中,数据处理与存储服务的核心设计思路与实施路径。
一、 方案设计的核心原则
- 数据隔离与安全第一:压测数据必须与线上真实数据在物理或逻辑上完全隔离,确保任何压测操作不会污染、影响线上业务数据。这是所有设计的首要前提。
- 数据真实性:压测使用的数据(如用户画像、商品信息、订单数据)需要在模型、量级、分布(如热点数据、长尾数据)上高度仿真线上环境,以模拟真实流量对系统的冲击。
- 可重复与可回溯:压测场景和数据应具备可重复执行的能力,便于问题定位和优化效果对比。所有压测操作需完整记录,支持事后审计与复盘。
- 自动化与效率:数据构造、环境准备、数据清理等过程应尽可能自动化,降低压测准备成本,提升压测频率和敏捷性。
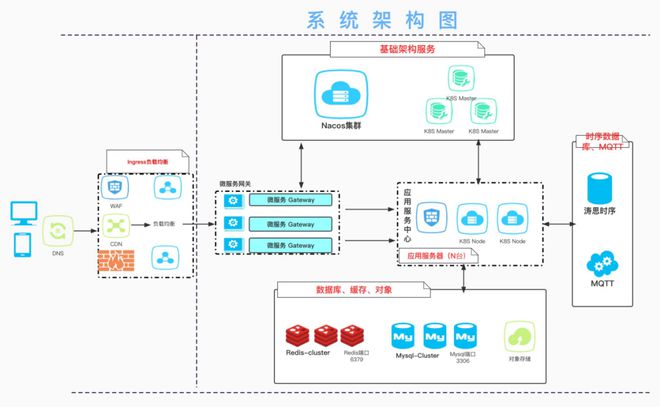
二、 核心组件与架构设计
有赞全链路压测的数据处理与存储方案,通常围绕以下几个核心组件构建:
- 影子库/影子表机制:
- 设计:在存储层(如MySQL、Redis)为参与压测的服务创建一套与线上结构完全一致的“影子”数据库或表。应用代码通过压测流量标识(如特定的Header或线程上下文),将压测请求的读写操作自动路由到影子存储,而线上流量则路由至线上存储。
- 实施:借助数据库中间件(如代理或客户端SDK)实现动态路由。这是实现数据物理隔离最彻底、最安全的方式。
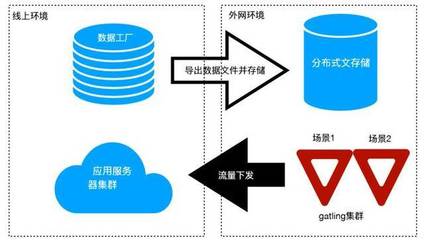
- 压测数据工厂:
- 设计:一个专门用于批量生成、管理压测数据的服务或平台。它负责根据业务规则,生成符合真实分布的海量仿真数据(如百万级用户、千万级商品SKU)。
- 实施:结合业务数据特征(如商品类目分布、用户地域分布),使用程序化脚本或数据生成工具(如基于Faker库或自研模板)来构造数据,并支持数据版本的快照管理。
- 数据流量染色与透传:
- 设计:在压测请求的源头(压测平台或流量发起端)为请求打上唯一的压测标识(如
X-Stress-Testing: true),该标识需要在全链路的所有服务调用(包括RPC、MQ消息、缓存操作)中进行无损透传。
- 实施:通过统一的微服务框架、RPC组件和消息中间件客户端进行拦截和上下文传递,确保数据路由策略在每一跳都生效。
- 缓存隔离方案:
- 设计:对于Redis等缓存服务,同样需要进行隔离。常见方案包括:
- Key前缀隔离:所有压测相关的缓存Key增加统一前缀(如
stress_)。
- 独立数据库/实例隔离:为压测分配独立的Redis DB或完全独立的Redis实例。后者资源隔离更彻底,但成本更高。
- 实施:在缓存客户端SDK中,根据流量标识动态拼接Key前缀或选择连接的数据库/实例。
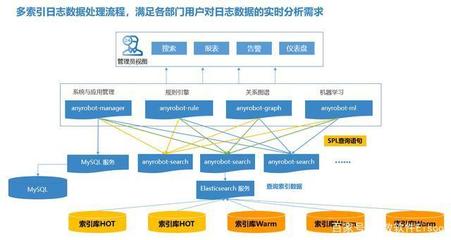
- 大数据与搜索服务隔离:
- 设计:对于Elasticsearch、HBase等用于搜索和分析的服务,同样需要建立影子索引或影子表。压测产生的数据分析流水线也应与线上隔离。
- 实施:在数据写入和查询的客户端,根据压测标识指向不同的索引或表。
三、 实施路径与关键步骤
- 存储层改造与影子环境搭建:
- 评估并梳理所有涉及数据读写的核心服务及其依赖的存储资源(DB、Cache、ES等)。
- 为这些资源搭建同构的影子环境,或配置影子库/表/索引。
- 应用代码与中间件改造:
- 改造微服务框架和中间件客户端(数据库驱动、缓存客户端、MQ客户端等),使其支持识别压测流量标识并进行相应的数据源路由。
- 这是工作量最大、最需谨慎的环节,需要进行充分的单元测试和集成测试。
- 压测数据构造与灌入:
- 利用“压测数据工厂”,根据压测场景(如大促峰值模型)生成基础数据(如用户、商品、店铺)。
- 通过专用工具或批量任务,将数据安全、高效地灌入影子存储环境,并验证数据的一致性与完整性。
- 链路验证与试压测:
- 在正式全链路压测前,进行多轮小规模的链路验证。验证内容包括:流量染色是否正确透传、数据读写是否准确进入影子库、业务逻辑是否正确执行、是否有数据泄露风险等。
- 压测执行与数据监控:
- 压测过程中,密切监控影子存储的各项指标,如数据库连接数、QPS、TPS、慢查询、缓存命中率、磁盘IO等,这些是定位系统瓶颈的关键依据。
- 数据清理与环境复位:
- 压测结束后,自动或手动触发影子环境的清理任务,清空压测数据,为下一次压测准备一个干净的环境。确保清理过程不影响线上。
四、 挑战与最佳实践
- 挑战1:数据关联与复杂性:电商业务数据关联性强(如订单关联用户、商品、优惠券)。解决方案是在数据构造阶段就维护好这些关联关系,并确保压测链路能正确处理这些关联逻辑。
- 挑战2:中间件与第三方服务:对于无法改造的第三方服务或中间件,需采用Mock或特殊策略(如使用白名单测试账号)来模拟。
- 最佳实践:
- 渐进式推进:从核心链路开始,逐步覆盖全业务。
- 常态化压测:将压测数据准备和环境维护流程固化、自动化,使之成为研发流程的一部分,而不仅仅是“大促”前的临时任务。
- 监控告警完善:针对影子存储建立独立的监控大盘和告警规则,与线上监控区分开,避免干扰。
###
有赞全链路压测的成功,离不开一套严谨、高效、安全的数据处理与存储方案。通过“影子库”为核心的数据隔离技术,结合全链路流量染色、自动化数据工厂以及全面的监控体系,不仅保障了压测过程对线上零干扰,更确保了压测结果能够真实反映系统在极限压力下的状态,为系统容量规划、性能优化与稳定性建设提供了坚实的数据支撑。这一套经过实战检验的方案,已成为保障分布式系统韧性的标准配置。